17 November 2018
The anatomy of a Heisenbug
As a programmer, I come across software bugs in all shapes and forms. A significant part of my job is finding those mistakes and fixing them. Finding the root cause of a bug often involves quite a bit of logical thinking. A theory for the cause is proposed. Tests are conducted. Depending on the observed behaviour during the tests, the theory is either invalidated or survives the tests just to be refined and tested again. This method is repeated until the exact lines in the program source code are found. For smaller problems, this entire process takes place in the programmer's head, so it is often overlooked that this is a valid application of the scientific method, albeit a small one. The same method can be applied in a wide variety of fields where unknown sources of errors need to be located. One example is the closely related field of electrical engineering, where hardware bugs can be tracked down with the same methodology, but different tools.
The difficulty of finding the root cause of a software bug is almost always directly proportional to the difficulty of reproducing it. That is, the harder it is to reproduce a problem, the harder it is to find its cause. Intuitively, it makes sense that the less opportunities you get to reproduce a bug in circumstances defined by you (e.g. with tools that provide additional data for analysis, or special source code modifications that isolate the bug by disabling other system components), the harder it is to gain information about it.
Reproducibility can be generalised by two dimensions:
- How long it takes, on average, to reproduce the problem
- How erratic the problem is, that is, the variance and randomness involved in the time it takes to reproduce the bug
However, in some cases, these two dimensions do not fully capture reproducibility. Because software systems are behaving far from randomly, they can exhibit peculiar behaviours that can almost be described as deterministically adversarial to anyone who seeks to analyze certain bugs. Buggy software that behaves like this is said to contain Heisenbugs, named after Heisenberg's uncertainty principle, because the software alters its behaviour as soon as it is studied. It is remarkable how these bugs come about just by pure chance, the sheer complexity of software and the fallible minds of humans.
This week, we found the cause of a heisenbug that has been unsolved for over four months. To give a bit of context, I write embedded software for measuring devices. These devices are comprised of a heterogenous, distributed set of electronic boards and processors. To keep the communication between these different boards sane, we use a protocol that was designed in-house and standardises the communication between all the boards. It is based on a C++ library that runs on about half a dozen different operating systems. This protocol takes care of almost everything we need to communicate: Dynamic routing, TCP-like integrity, order and single-delivery guarantees over various interfaces, serialization and more. To create a network, the user of this library only has to instantiate a Switchboard and hook it up to interfaces like pipes that connect to other Switchboards.
I wrote and maintain the firmware updater that is responsible for applying the updates to all these subsystems, considering order of installation and rebooting, hardware compatibilities and topology. Once the update file is uploaded and the update mechanism triggered, the updater runs autonomously and executes a couple dozen steps as described in the update manifest. A user can be present to monitor the update progress, or they can just turn off their Windows PC and let the measuring device complete the update on its own.
This updater had a rare but persistent problem that was almost impossible to debug: In some cases, the communication to a Switchboard, let's call it T for brevity, was cut off completely for a short period of time, causing all commands sent to T to time out and never arrive, thus failing this part of the update process. Furthermore, the problem was so rare that in four months, not a single bug report was filed, except for my own. In fact, I was one of the only people who was affected by this problem, but the bug behaved so erratically that sometimes, days of automatic update tests showed nothing, whereas a single installation in the morning after getting into office reproduced it. The weird thing was that the connection to T seemed to reappear out of the blue, often no more than 30-40 seconds after it was lost. None of our data interfaces seemed to be broken, and all the physical links were intact. The problem also appeared on multiple devices, so we could rule out random hardware faults.
It was only after our integration test system started to reproduce the updater bug in a reproducible fashion that we could gain some new insights. We made the remarkable discovery that as soon as a client is hooked up to our system - no matter what client, it could be an official GUI client or a lightweight debug tool only used internally - the problem would disappear. So this is your classic Heisenbug! When you look at it, it goes away. This is also why hardly anyone else reproduced the bug - the standard updater stays connected throughout the update to monitor progress, and only specialised tools we used for development and testing actually disconnected from the device and let it run fully autonomously.
So, after finding that out, the big question is still unanswered: What's happening here? Why does the presence of a client affect internal communication to Switchboard T? To answer this question, we have to understand the topology of the system. The following picture shows the three physical devices involved, depicted as large rectangles:
- A Windows PC, which is the client
- A controller, which is in between and runs the updater
- A sensor, which needs to be updated
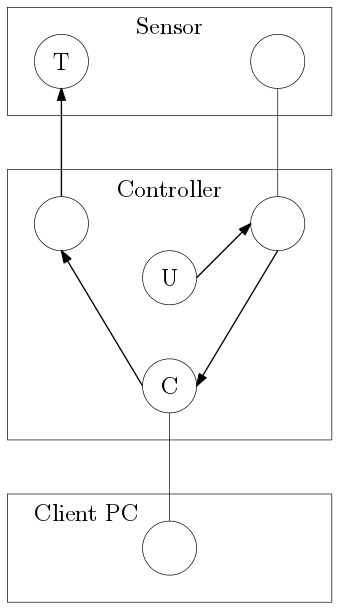
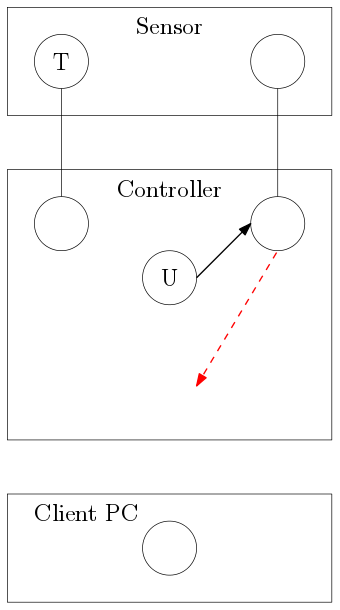
When a client is connected, a Client Switchboard C is created. The instantiation of this Switchboard allows communication from the updater U to the target device T via dynamic routing. As soon as the client disconnects, the Client Switchboard C is destroyed and the link is broken. The updater should have never sent data via this route and was hooked up improperly. Note that the two Switchboards in the sensor are isolated from each other on purpose. A Client Switchboard C connects these two isolated boards together, which leads to unexpected bugs like this one. Since most of our debug tools are such clients, it was nearly impossible to debug this problem because it stopped happening.
Solving this problem should be substantially easier than finding it.
Key takeaways:
- Connecting a tool changes the network topology
- Integration tests are worth it
- Dynamic routing can be dangerous
- Our tools to map and debug network topologies are inadequate and need to be improved
- We need to prevent Switchboards from connecting isolated networks