30 May 2021
The weirdest bug I've ever encountered
I am responsible for the reliability of the firmware updates on our devices and this work never gets boring. The thing about firmware updates is that by definition, every bug is caused by the updater because before installing the affected version, the bug was not present. You could say that updates are the cause and the solution of all software problems. So, a lot of update bug reports that find their way to me have nothing to do with the updater per se, they just manifest themselves immediately, giving the impression that the updater is broken. But I'm getting ahead of myself, so let's start from the beginning.
A new bug comes in: Update failed from version X to version Y, error getting log files from sensor. After that, the user manually rebooted the machine and it worked again.
I connect to the machine and download all the logfiles. In the logs, I see that the update installed successfully. After the reboot which starts the newly installed firmware, there were some minor problems: Some processes took a bit longer to start than expected. Other than that, the log looks clean, no errors that could explain this behaviour.
I try to install the affected Firmware version Y on various devices. The problem does not appear. But as luck has it, a co-worker encountered the problem and had the presence of mind to recognize it and leave the system undisturbed for analysis. Connecting to the system is difficult because it is laggy and slow. The device can barely handle simple commands. Weird. Let's run top.
60 processes; 646 threads;
CPU states: 16.0% user, 35.0% kernel
CPU 0 Idle: 55.4%
CPU 1 Idle: 42.4%
Memory: 0 total, 543M avail, page size 4K
PID TID PRI STATE HH:MM:SS CPU COMMAND
1 12 10 Run 1:51:21 17.72% kernel
1 5 10 Run 2:13:10 17.04% kernel
602168 1 10 Rdy 3:30:01 13.98% ps
229398 1 21 Rcv 0:09:32 0.67% smb-tunnelcreek
778301 1 10 Rply 0:00:00 0.62% top
253978 2 21 NSlp 0:05:43 0.40% devi-tsc2007
1 6 10 Rcv 2:08:09 0.25% kernel
7 2 21 Rcv 0:01:41 0.07% io-pkt-v4-hc
581675 15 10 CdV 0:00:17 0.07% telescope
8200 9 21 Rcv 0:00:35 0.05% io-usb
Min Max Average
CPU 0 idle: 55% 55% 55%
CPU 1 idle: 42% 42% 42%
Mem Avail: 543MB 543MB 543MB
Processes: 60 60 60
Threads: 646 646 646
Okay, we immediately have some clues here. The QNX kernel is doing a lot of stuff and so is ps. We see that the CPU load of the two cores is about 50%. But we know that the system has hyperthreading and only has one physical core, so the real load is actually more like 100%. To me, it looks like ps is saturating the core completely, the kernel load is probably caused by whatever ps is doing.
Who is calling ps? With ps -ef we can see the PPID, the parent process id, to track down who spawned this process. Ironically, we use ps to debug this ps problem. Like this, I find that it was spawned by the shell sh, which in turn was spawned by one of our proprietary processes. Equipped with the knowledge of which process is affected and analysing the logs to find out where this process got stuck, I quickly find the offending line of code. It looks like this: int rc = system( "ps -e | grep Foo" ); where Foo is some program whose presence we need to check. Not the prettiest way to implement it, but it is legacy code that worked for many years. I also see that this code only gets executed on certain old hardwares. This explains why the problem never reproduced on most systems, they have newer hardware. Even on the old hardware, it is exceedingly rare and hard to reproduce. Killing the offending ps process, which loops infinitely otherwise, unblocks the system and restores normal operation.
We now know a lot about this problem, but what is the root cause? The ps program causes 100% CPU load... What is this? We use QNX 6.6 and ps is supplied as a closed source binary. To understand this problem, we need to analyse the ps utility itself. We can already do that at the assembly level. The QNX Momentics IDE has an option "Attach to Remote Process via QConn" with which I can tap right into the running process. We see that it is stuck in a loop that calls devctl() over and over again. The return value of this devctl() is 3 which is ESRCH: No such process. This error comes straight from MsgSendv_r which returned -3. It documents that ESRCH means The server died while the calling thread was SEND-blocked or REPLY-blocked..
Okay, so, ps gets stuck in an infinite loop. Dare I say it: Do we have a ps bug on our hands? The QNX ecosystem is generally quite robust. In the past, it almost always ended up being my own mistake when I suspected problems in QNX and its utilities. But how can the infinite loop seen in live assembly debugging be explained with a user error of ps?
At this point, an intermezzo with some QNX history is in order. A bit more than a decade ago, the QNX source code was available to the public. Back then, QNX had a vibrant open source community. People would experiment with the kernel, write various useful utilities and help each other in forums. QNX even had a fully featured Desktop GUI, ran Firefox and was self-hosting, so you could develop for QNX right on QNX itself with full IDE and compiler support. It was beautiful. Then QNX was bought, source code access was revoked and the community largely withered away. Questions were increasingly asked via private support tickets directly to QNX, locked away from the public. QNX know-how becomes harder and harder to acquire, open source software for modern QNX releases is essentially non-existent and the driver situation is a catastrophe. The QNX kernel is the most beautiful and interesting kernel I have ever had the pleasure of working with, but it lies in the shackles of corporate ownership.
Back to the bug. So there is old QNX source code lying around. Do you think anyone has modified the source code of the ps utility throughout the last 15 years? Me neither! Let's dive right into the old code.
The old ps utility compiles for QNX 6.6 on the first try. Nice! It works just like the closed source binary we have. I install my newly compiled ps, write some software to automatically test reboots in a loop overnight and am able to reproduce the problem with this custom ps binary. Perfect! Now we can use the "Attach to Remote Process via QConn" feature again, but this time we have the source code of our ps. I already read the source code of the old ps before I did all of this, and I already had my suspicions as to which devctl() call was being repeated endlessly in the loop, so it comes as no surprise when the debugger points me to the following line:
if (devctl (fd, DCMD_PROC_TIDSTATUS, &tinfo, sizeof (tinfo), 0) == EOK)
The root cause of the bug is the following. For every process in the /proc directory, ps opens a file descriptor to this process' address space (as) file to read the process information to be displayed. For each process, it loops through all the threads of this process, and the bug is that this loop has insufficient termination criteria (in other words, in some cases, it loops infinitely). The problem occurs when the process whose threads we want to inspect terminates right before ps enters this loop. In that case, the devctl() call fails and as you can see in the following simplified snippet, it will never terminate because the if-clause is never entered.
while (1)
{
if (devctl (fd, DCMD_PROC_TIDSTATUS, &tinfo, sizeof (tinfo), 0) == EOK)
{
//[...]
tcount++;
// stop when we have gone through each thread, or when
// the user only want process info
if ((usingThreads == 0) || (tcount == info.num_threads))
break;
}
tinfo.tid++;
}
I also verify this hypothesis by halting the ps process in the debugger, killing the process whose threads we are about to inspect and resuming ps and it hangs in precisely the same way. This is what it looks like in the QNX Momentics IDE:
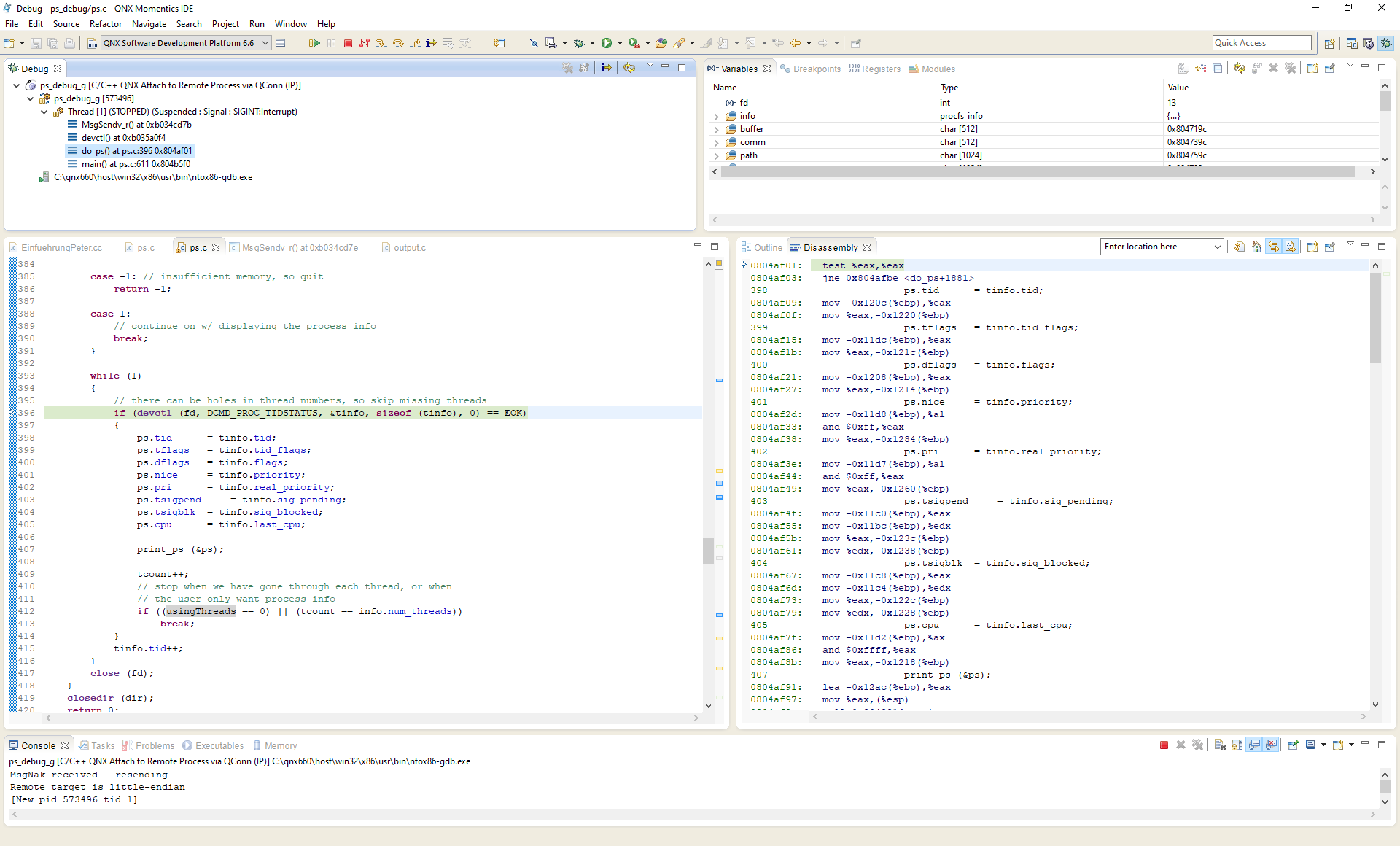
After this analysis, I'm quite sure that this 15 years old bug is still alive and well in our closed source binary.
Why did this problem suddenly appear in our firmware? We can only speculate, it must have been changes in the scheduling order or timing at boot time. The bug is a race condition, so it can rear its ugly head whenever it wants. The affected code was old and deployed in production for many years.
How did I fix it? I briefly considered shipping our own ps utility, but I was still unsure about other bugs that might potentially be fixed in the latest closed source binary, those fixes would be lost again if I revert to the old open source version. At the end of the day, I decided to comb through our code base and just eliminate the usage of ps in non-interactive code, there weren't that many instances. Our ps utility remains buggy as it is, but it's pretty much impossible to reproduce this bug in an interactive terminal, and our firmware no longer uses it. Needless to say, this particular update problem never occurred again after that.
Does the ps bug still exist in QNX ecosystems more recent than QNX 6.6? Most likely, yes. If it was open source, I would fix it and send a pull request. Because it's not, they have to deal with the issue themselves. Maybe in a decade, an unfortunate soul runs into this bug again. Let's hope this blog post will save them some trouble.
What do we learn?
- No matter how battle-tested and old the code and how reputable the distributor - the code contains bugs.
- Old bugs can manifest themselves seemingly out of nowhere, caused by subtle changes in timing or memory layout.
- Whenever the file system is involved, there is a significant danger that bugs are caused by race conditions.
- Closed source operating systems and ecosystems are a pain to debug. Even old open source releases help.
- Do not use interactive shell utilities in non-interactive code. Avoid
system()whenever possible. Not only is the performance terrible, it can give rise to bugs like this one. - Make sure your loops terminate. Bounded loop variants that increase or decrease strictly monotonically guarantee loop termination. Don't be too clever with loops!
Post comment
Comments
Zefoy is a platform that provides tools and resources related to social media engagement.
If you're looking to learn more, visit <a href="https://zefoy.store/">Zefoy</a> for additional information and updates.
Always use third-party services responsibly and review their terms before using them.
reply
I will definitely recommend your website to everyone. You have a very good gloss. Write more high-quality articles. I support you.
reply
Bij Kami Webdesign hebben we meer dan 6 jaar ervaring en 50+ websites gebouwd. We zien regelmatig waar het fout gaat bij goedkope websites: trage laadtijden, slechte technische opbouw en websites waar je amper zelf content kunt aanpassen zonder iets kapot te maken. Vaak ziet het er op het eerste gezicht prima uit, tot je er echt mee moet werken.
reply
That story about the bug where variables were swapped because of a typo in a config file is exactly the kind of thing that keeps me up at night debugging. After a day of wrestling with code, I like to unwind by experimenting with a <a href="https://graffiti-generator.art">graffiti creator</a> to create street art designs—it's a great way to shift gears and be creative without worrying about syntax errors.
reply
Really impressed! Everything is very open and very clear clarification of issues. It contains truly facts. Your website is very valuable. Thanks for sharing.
reply
If you want complete knowledge about ALL RUMMY, visit https://toprummys.com Explore app reviews, beginner-friendly guides, bonus details, gameplay tips, and responsible gaming advice. Learn how different rummy formats work and make informed decisions before joining any platform.
reply
As a developer, I've seen my share of bizarre bugs, but this one takes the cake. It reminded me of how weird tech can be—and also how useful AI can be for creative tasks like interior design. I've been experimenting with an <a href="https://archoneai.com/ai-interior-design" target="_blank" rel="nofollow noopener noreferrer">AI interior design generator</a> to quickly visualize room transformations.
reply
I have read so many articles or reviews concerning the blogger
lovers except this paragraph is truly a pleasant piece of writing, keep it up.
reply
Traditional elegance meets modern sophistication in the <a href="https://houseoffakirchand.com/collections/dupatta">Wedding Dupatta Collection</a> available at House Of Fakir Chand.
reply
Met een gedurfde en moderne kijk op herenmode zet "DealByEthan" de trend op het gebied van premium ondergoed, designer zwemkleding (swimwear) en prêt-à-porter kleding voor mannen. Door ergonomische snitten, innovatieve materialen en een verfijnde esthetiek te combineren, zijn onze collecties ontworpen om elke dag absoluut comfort te bieden en het mannelijk silhouet te accentueren.
reply
Great resource on Maven Trading! The content is informative, well organized, and easy to understand, providing valuable insights into the firm's funded trading programs. A helpful page for traders researching prop firms and exploring funded trading opportunities.
reply
Great resource on FundingPips! The content is informative, well organized, and easy to understand, providing valuable insights into the firm's funded trading programs. A helpful page for traders researching prop firms and exploring funded trading opportunities.
reply
풀싸롱 관련 정보를 찾다가 방문했는데 정말 도움이 많이 되었습니다. 핵심 내용이 잘 정리되어 있어서 이해하기 쉬웠어요. 좋은 글 감사합니다 <a href="https://gangnamya.clickn.co.kr/">풀싸롱</a>
reply
Your means of describing the whole thing in this paragraph is actually good, all be able to without difficulty understand it, Thanks a lot.
reply
TreeServicesKnoxville provides professional tree care solutions including tree removal, trimming, pruning, and emergency services to keep properties safe and beautiful. Their experienced team focuses on maintaining healthy trees while improving the appearance of residential and commercial landscapes. Learn more about reliable tree care services at <a href="https://treeservicesknoxville.net/">treeservicesknoxville</a>.
reply
The weirdest bug I've ever encountered is such an interesting post describing the solution, and we can learn from it. So we can resolve it in a short time without worrying about it. There are many developers facing troubles and in this way they can learn and get experts in resolving these bugs.
reply
It's always the edge cases that reveal how complex AI systems really are.
reply
A bug that seems impossible at first can uncover unexpected interactions between speech recognition, scheduling, and customer intent.
reply
It's always the edge cases that reveal how complex AI systems really are.
reply
It's always the edge cases that reveal how complex AI systems really are. A bug that seems impossible at first can uncover unexpected interactions between speech recognition, scheduling, and customer intent. Stories like this show why continuous testing is so important for an [url=https://www.nuvarisai.com/ai-receptionist-tacoma-wa.html]Ai receptionist Tacoma[/url] or anywhere else.
reply
Dr. Arun Reddy Mallu is regarded as one of the Best Orthopedic Surgeons in Hyderabad, offering advanced robotic knee replacement and sports injury treatments with excellent patient care. Looking for a trusted sports injury specialist in Hyderabad? Dr. Arun Reddy Mallu is highly experienced in ACL Reconstruction surgery, shoulder arthroscopy, and robotic joint replacement procedures.
<a href="https://drarunreddymallu.com/">https://drarunreddymallu.com/</a>
reply
The non-surgical hair growth procedures developed by Dr. Stuti Khare Shukla are genuinely groundbreaking. The success stories and thorough explanations of FDA-approved Hair Growth Booster® treatment pleased me. Her accomplishments, such as winning the 'ET Inspiring Woman of India' award and being designated the 'Youngest Dermatologist of India,' speak for themselves. I strongly advise anyone searching for cutting-edge dermatological remedies to visit her official website.
<a href="https://drstutikhareshukla.com/">https://drstutikhareshukla.com/</a>
reply
Great to see a company providing complete digital marketing solutions like SEO, social media marketing, branding, and growth strategies under one roof. Strong marketing creates strong brands.
<a href="https://thesapmedia.com/">https://thesapmedia.com/</a>
reply
That's a good idea. A personalized gift shows that you actually took the time to make something specially for them. While even parents who take 5 minutes to buy something are appreciated, it
reply
Terra Hill Brochure is a beautifully designed and informative guide that highlights the development’s layouts, features, and lifestyle offerings in a clear and engaging way. It provides potential buyers with valuable insights into the property, making it easier to explore its vision and amenities. Terra Hill Brochure reflects professionalism, quality, and the promise of refined modern living.
reply
Sora Condo Brochure is a beautifully presented and informative guide that showcases the development’s features, layouts, and lifestyle offerings in a clear and engaging way. It helps potential buyers explore the property with confidence by providing valuable insights into its design and amenities. Sora Condo Brochure reflects professionalism, quality, and the vision of modern, comfortable living.
reply
The weirdest bug I've ever encountered appeared only on one device and disappeared whenever debugging tools were enabled. Tracking it down took longer than fixing it, but it was a great reminder of how unpredictable software can be. For secure and convenient access management solutions, check out <a href="https://sso-id.se/">sso-id</a>.
reply
Great post. Thanks for sharing. That was a solid read. I really like how you got straight to the point while still leaving me with something to think about. It's rare to come across a blog post that is both simple and thoughtful. Thanks for putting this out there.
reply
The weirdest bug I’ve ever encountered was one that only appeared under very specific conditions, making it difficult to reproduce and even harder to debug. It seemed random at first, but later turned out to be caused by an unusual interaction between cached data and timing issues in the system. Solving it required careful logging and step-by-step testing to uncover the root cause.
For more insights, resources, and helpful ideas, visit <a href="https://flavorsuggest.co/">flavorsuggest</a> and explore content designed to help you discover useful tips and solutions.
reply
The weirdest bug I’ve ever encountered was one that seemed completely random at first, causing unexpected behavior that was hard to trace. After digging deeper, it turned out to be a small logic issue that created a chain reaction in the system.
These kinds of bugs remind developers how important debugging and attention to detail really are when working on complex projects.
For more interesting content and useful updates, you can visit <a href="https://heyteamenu.se/">heyteamenu</a> to explore helpful resources and ideas.
reply
The Continuum is widely praised on property websites for its rare freehold tenure, expansive luxury concept, and prime District 15 location that blends East Coast charm with modern sophistication. Featuring around 816 thoughtfully designed residences across a unique dual-site development connected by an overhead bridge, it offers spacious layouts, premium finishes, and a full suite of resort-style facilities designed for elevated living.
reply
在 Premier Visa Group,我們不僅僅是移民顧問——我們是您在移民、簽證和全球身分規劃方面值得信賴的專業合作夥伴。 <a href="https://www.premiervisagroup.com/zh-cn">多米尼克护照</a>
reply
Its like you read my mind! You seem to know a lot about this, like you wrote the book in it or something. I think that you could do with some pics to drive the message home a little bit, but instead of that, this is great blog. A fantastic read. I will definitely be back.
reply
That's a wild debugging scenario; tracking down a process spawned by itself sounds like a true Gordian knot of system issues! It makes me think about how crucial clear logging and process visibility are, which is something we always strive for when setting up our event capture systems
reply
Wow, that sounds like a truly bizarre firmware issue where `ps` itself was the culprit—I've never heard of a diagnostic tool causing the very slowdown it's meant to monitor!
reply
I am usually to blogging and i genuinely appreciate your content regularly. This content has truly peaks my interest. I will bookmark your web site and maintain checking achievable details.
reply
This is such a deeply relatable and thought-provoking piece. The way you articulate those quiet, internal struggles really resonates, and the writing feels incredibly raw and honest. Thanks for sharing this perspective—it's a comforting reminder that we're not alone.
reply
Competitive players enjoy 334 Rummy because of the exciting real-time matches available on the platform. Users can challenge opponents and participate in tournaments to improve their gameplay skills. Referral bonuses and cashback offers help make the experience more rewarding. Smooth performance and secure payment methods improve overall trust among users. Learn more:
https://334rummyapp.com
https://334rummygame.com
reply
I’m still learning from you, as I’m trying to achieve my goals. I definitely love reading everything that is written on your site. Keep the articles coming. I liked it!
reply
This blog post highlights the persistent nature of bugs in software, especially in closed-source systems. The author's experience with the ps utility serves as a reminder that even long-standing code can harbor unexpected issues. It's crucial to avoid using interactive tools in automated contexts.
reply
The insights shared about dealing with the race condition bug in the firmware are quite enlightening. It's a reminder of how legacy code can present unexpected challenges. The decision to eliminate the usage of the ps utility in non-interactive code was a smart move.
reply
The challenges of firmware updates highlighted here are fascinating. I
reply
Honestly, this was such a good read. I really liked how you didn't just stay on the surface but actually explained the thinking behind it. You don't see that kind of depth in blogs very often. Thanks for writing this.
reply
River Modern is widely praised on property websites for its rare riverfront location in prestigious District 9 and seamless direct connection to Great World MRT station. Featuring around 455 thoughtfully designed luxury residences across two 36-storey towers, the development blends modern architecture with lush landscaping and panoramic views of the Singapore River and city skyline.
reply
One of the weirdest bugs I’ve ever encountered was caused by a single hidden character in the code that broke an entire application for hours. Everything looked correct, yet the system kept failing until the invisible issue was discovered. Experiences like these remind developers how important attention to detail is in technology. For smart digital networking and modern business card solutions, check out <a href="https://rehmatcard.se/">rehmatcard</a>.
reply
Coastal Cabana is widely praised on property websites for its rare seaside executive condominium concept and prime location along Jalan Loyang Besar in Pasir Ris. Featuring around 748 thoughtfully designed units across multiple residential blocks, the development offers spacious layouts, resort-style facilities, and stunning coastal surroundings that create a relaxing yet modern lifestyle environment.
reply
SSOID is a reliable digital identity platform that provides secure and seamless access to online services.
It helps users manage authentication and account access with a simple and user-friendly experience.
Visit <a href="https://ssoid.se/">SSOID</a> to explore more features and services.
reply
Rummy Ola is a popular online card gaming platform inspired by the traditional game of rummy and designed for smooth mobile gameplay. Many users enjoy Rummy Ola because of its simple interface, interactive features, and beginner-friendly gaming experience. Players can explore online card gameplay, learn strategies, and enjoy multiplayer entertainment in a digital environment. For more information about Rummy Ola, visit <a href="https://rummyolas.com/">Rummy Ola</a> and explore its online gaming features. Users should always play responsibly and follow local laws related to online gaming activities.
reply
I would like to thank you for the efforts you have put in penning this site. I’m hoping to view the same high-grade content by you later on as well. In truth, your creative writing abilities has motivated me to get my own, personal website now.
reply
<a href="https://royalxcasino-app.com.pk/">Royal X Casino</a> offers exciting online casino games, easy login, daily bonuses, and secure payments. Explore gameplay, features, and earning opportunities today.
reply
안전하고 신뢰할 수 있는 바카라사이트 선택법부터 게임 규칙, 필승 전략, 자주 묻는 질문까지. 온라인 바카라 초보자도 전문가처럼 즐길 수 있는 완벽 가이드. <a href="https://바카라sites.isweb.co.kr/">바카라사이트</a>
reply
Vans Medical Equipment has been your trusted partner in providing top-quality medical supplies to meet the diverse needs of healthcare professionals and individuals alike. With a commitment to excellence, we are dedicated to enhancing the health and well-being of our customers by offering a comprehensive range of medical equipment and supplies.
reply
Teaching English online has become a flexible, rewarding career path—and you don’t need a university degree to get started. By focusing on the right certifications, tools, and platforms, anyone with strong English skills can build a thriving online teaching business.
reply
Positive site, where did u come up with the information on this posting? I'm pleased I discovered it though, ill be checking back soon to find out what additional posts you include.
reply
Thomson Reserve is widely praised on property websites for its exceptional nature-integrated living concept and prime Upper Thomson location right beside the Central Catchment Nature Reserve. The development, featuring around 1,200+ thoughtfully designed units, offers a rare blend of lush greenery, modern architecture, and resort-style facilities that create a tranquil yet upscale residential environment.
reply
This insightful post highlights the challenges of dealing with legacy code and race conditions. It's a reminder of the importance of maintaining and updating software to avoid such bugs.
reply
This post highlights the persistent nature of bugs in software, especially in closed-source systems. It's a reminder that even the most trusted code can harbor issues that resurface unexpectedly. For those looking to escape the complexities of debugging, why not take a break and enjoy some fun? Check out <a href=""></a> for an exhilarating gaming experience!
reply
The insights shared regarding the persistence of bugs in code, especially in closed-source systems, are quite enlightening. It’s a reminder that no software is immune to issues, regardless of its age or reputation. This reinforces the importance of thorough testing and vigilance in software development.
reply
The troubleshooting process described highlights the complexity of software updates and their unintended consequences. It's fascinating how updates can both solve and create issues.
reply
This was a solid read. I like how you got straight to the point but still left me with something to think about. Feels rare to come across a blog post that's simple and thoughtful at the same time. Thanks for putting this out there.
reply
Ontdek onze handmatig geselecteerde collectie van 's werelds meest gewilde sportwagens
reply
What a fantastic blog! I enjoy reading your posts. Good luck with your paintings! Thanks for reading! You could be of great assistance to a lot of people who are searching for this information.
reply
All Rummy Apps with Flexible Withdrawal Methods
Flexible withdrawal options make it easier for players to access their winnings. Many apps support multiple methods like UPI, bank transfer, and e-wallets. This ensures convenience and quick payouts. Players should check withdrawal limits and processing time before choosing an app. To explore apps with flexible withdrawal options, visit https://allrummys.com/all-rummy-apps/
.
reply
Parktown Residences is widely praised on property websites for its large-scale integrated living concept and prime location in Tampines North, one of Singapore’s fastest-growing hubs. Featuring around 1,190 thoughtfully designed units, the development seamlessly combines residential living with retail spaces, a bus interchange, community facilities, and direct access to the upcoming MRT station—offering unmatched everyday convenience.
reply
The insights shared about the ps bug and its implications in closed source systems are quite enlightening. It underscores the importance of careful coding practices and the potential pitfalls of relying on older code.
reply
Camuvo is a free random sex video chat platform built for adults who want instant, anonymous connections with strangers worldwide. Our mission is simple: make it effortless to meet new people face-to-face through live webcam chat.
reply
How to Get All Rummy Bonus Instantly
Getting an all rummy bonus is one of the main reasons players download rummy apps. Most platforms offer signup bonuses like ₹41, ₹51, or even higher rewards. These bonuses can be used to play games and win real money.
You can explore multiple offers on
👉 https://allrummydownloads.com
Different apps provide different types of bonuses such as referral rewards, cashback, and deposit offers. According to online gaming guides, many rummy platforms give instant rewards to attract new users . Always read terms before using bonuses to maximize your benefits.
reply
Guyloo is a free random gay webcam chat platform that prioritizes visual quality and seamless connections. We created Guyloo for men who value a premium cam experience without the cost or complexity that usually comes with it.
reply
Artisan 8 is widely praised on property websites for its rare freehold status, boutique scale, and thoughtfully crafted mixed-use concept in the heart of Sin Ming. With just 34 exclusive residential units and integrated commercial spaces, it offers a unique blend of privacy, convenience, and modern urban living.
reply
Every Camruletka chat is private, fast, and designed for natural communication. You're always in control—switch to the next person at any time or stay and chat as long as you want.
reply
<a href=''https://notaphiluhub.com/product/buy-counterfeit-10-aud-notes/">buy counterfeit $10 AUD Notes</a>
<a href=''https://notaphiluhub.com/product/buy-couterfeit-5-aud-bills/''>$5 AUD Bills</a>
<a href=''https://notaphiluhub.com/product/buy-counterfeit-50-cad-bills/''>buy counterfeit $50 CAD Bills</a>
<a href=''https://notaphiluhub.com/product/buy-counterfeit-20-cad-bills/''>$20 CAD Notes </a>
<a href=''https://notaphiluhub.com/product/buy-counterfeit-10-cad-bills/''>$10 CAD Bills </a>
<a href=''https://notaphiluhub.com/product/5-cad-bills/''>Buy Counterfeit $5 CAD Bills </a>
<a href=''https://notaphiluhub.com/product/buy-counterfeit-e100-euro-notes/''>Buy Counterfeit €100 Euro Notes </a>
<a href=''https://notaphiluhub.com/product/e50-euro-bills/''>Buy Counterfeit €50 Euro Notes</a>
<a href=''https://notaphiluhub.com/product/e20-euro-bills/''>Buy Counterfeit €20 Euro Notes</a>
<a href=''https://notaphiluhub.com/product/e10-euro-bills/''> buy counterfeit €10 Euro Bills</a>
<a href=''https://notaphiluhub.com/product/e5-euro-bills/''>Buy Counterfeit €5 Euro Notes</a>
<a href=''https://notaphiluhub.com/product/50-usd-bills/''> buy counterfeit $50 USD Notes</a>
<a href=''https://notaphiluhub.com/product/20-usd-bills/''>Buy Counterfeit $20 USD Notes</a>
<a href=''https://notaphiluhub.com/product/10-usd-bills/''>buy counterfeit $10 USD Notes</a>
<a href=''https://notaphiluhub.com/product/5-usd-bills/''>buy counterfeit $5 USD Notes</a>
<a href=''https://notaphiluhub.com/product/5-gbp-bills/''>Buy Counterfeit £5 GBP Notes</a>
<a href=''https://notaphiluhub.com/product/50-gbp-bills/''>Buy Counterfeit £50 GBP Notes</a>
<a href=''https://notaphiluhub.com/product/20-gbp-bills/''> Buy Counterfeit £20 GBP Notes</a>
<a href=''https://notaphiluhub.com/product/10-gbp-bills/''> Buy Counterfeit £10 GBP Notes</a>
<a href=''https://notaphiluhub.com/''>untraceable banknotes for sale</a>
<a href=''https://notaphiluhub.com/product-category/buy-aud-bills/"buy AUD Bills</a>
<a href="https://notaphiluhub.com/product-category/buy-cad-bills/"Buy CAD Bills</a>
<a href=''https://notaphiluhub.com/product-category/buy-euro-bills/"Buy EURO Bills</a>
<a href=''https://notaphiluhub.com/product-category/buy-gbp-bills/"buy GBP Bills</a>
<a href=''https://notaphiluhub.com/product-category/buy-usd-bills/"buy USD Bills</a>
reply
Professional bodyguard services in Tokyo delivered by former Israeli Special Forces and Shin Bet operatives. We provide discreet, low-profile protection for executives, business travelers, and high-net-worth individuals, including secure transportation, route planning, and full risk management. Every operation is tailored to your itinerary and conducted with complete confidentiality across Tokyo and Japan.
reply
Arina East Residences is widely praised on property websites for its rare freehold status, exclusive boutique scale, and prime waterfront location in Tanjong Rhu. With only about 107 thoughtfully designed units, the development offers a private and tranquil living environment complemented by modern architecture, premium finishes, and full lifestyle facilities.
reply
I was recommended this blog by way of my cousin. I’m not sure whether or not this post is written through him as nobody else recognise such precise about my trouble. You’re incredible! Thanks!
reply
Buy party wear dress for baby boy and kids at the best prices from Ministitch. Our boys party wear dresses, and birthday dresses for boys are exclusive for kids. https://ministitch.in/
reply
Buy party wear dress for baby boy and kids at the best prices from Ministitch. Our boys party wear dresses, and birthday dresses for boys are exclusive for kids. <a href="https://ministitch.in/">party wear dress for baby boy</a>
reply
I think this is one of the most vital information for me. And i am glad reading your article. But want to remark on few general things, The site style is great, the articles is really great. Good job, cheers
reply
Parivahan services in India help citizens easily access transport-related facilities online, including vehicle registration, driving licenses, and permit information. Platforms like <a href="https://parivahansewak.com/">parivaha sewa</a> provide helpful guidance and updates so users can understand government transport services more clearly. It makes navigating transport rules and digital services much simpler for everyday users.
reply
Welcome to Joingy, the ultimate destination to kickstart a random video chat with people from all around the globe. Instantly connect with complete strangers in a fun, anonymous, and spontaneous environment! Whether you’re looking to chat with random girls or boys, the possibilities are endless.
reply
Welcome to Joingy, the ultimate destination to kickstart a random video chat with people from all around the globe. Instantly connect with complete strangers in a fun, anonymous, and spontaneous environment! Whether you’re looking to chat with random girls or boys, the possibilities are endless.
reply
There are certainly a lot of details like that to think about. That is an excellent <a href="https://lsm999dna.online/">lsm99bet</a> point to bring up. I use the thoughts above as basic motivation but plainly there are inquiries like the one you bring up where one of the most essential thing will be working in sincere good faith.
reply
zefoy is an online platform that helps users enhance their social media engagement by providing easy-to-use growth tools. It is especially popular among content creators who want to increase their reach and visibility on platforms like TikTok. With a simple interface and quick access to features, <a href="https://www.zefoy.cloud/">zefoyfollower</a> makes it convenient for users to boost their online presence efficiently.
reply
Fascinating deep dive! Never thought a seemingly simple `ps` call could bring down a system. Makes me appreciate robust error handling even more. I wonder if the new Seedance 2 Video Generator would have shown a similar issue with CPU usage.
reply
The Pinery Residences Showflat offers a wonderful glimpse into the modern lifestyle and thoughtful design showcased by Pinery Residences. Property websites often praise its stylish interiors, efficient layouts, and quality finishes that reflect both comfort and contemporary elegance.
reply
Rummy Pride- Play Online Rummy Games and Earn Real Money
Online rummy is one of the most popular skill-based card games in India, offering both entertainment and real cash rewards. Among the many platforms available today, Rummy Pride is a reliable application that allows players to enjoy rummy games and earn real money using their skills and strategies.
Download now- https://rummyappsbonus.com/rummy-pride/
reply
Rummy Apple – Play Online Rummy Games and Earn Real Money
Online rummy is one of the most popular skill-based card games in India, enjoyed by millions of players for entertainment as well as real cash rewards. Among the growing number of platforms available, Rummy Apple is a reliable application that allows users to play rummy games and earn real money through smart gameplay and strategy.
Download now- https://rummyappsbonus.com/rummy-apple/
reply
Rummy Most– Play Online Rummy Games and Earn Real Money
Online rummy has emerged as one of the most popular skill-based card games in India. Among the many platforms available today, Rummy Most stands out as a reliable application where players can enjoy exciting rummy games and earn real money through their skills and strategies.
Download now- https://rummyappsbonus.com/rummy-most/
reply
Rummy Apps Bonus – Your Ultimate Guide to Real Money Rummy Apps
Online rummy has exploded in popularity in recent years, becoming one of the most engaging and skill-based card games available on mobile devices. Whether you're a beginner or an experienced player, finding the right rummy app makes all the difference — especially if you want to earn real money while playing. Visit now- RummyAppsBonus.com
reply
Rummy Pride – Play Online Rummy Games & Earn Real Money
Online rummy is one of the most popular skill-based card games in India, and Rummy Pride is a trusted platform where players can enjoy rummy games and earn real money. With multiple rummy formats, attractive bonuses, and a secure gaming environment, Rummy Pride is suitable for both beginners and experienced players.
Download now- https://toprummys.com/rummy-pride/
reply
Rummy Apple – Play Online Rummy Games & Earn Real Money
Online rummy is one of the most popular skill-based card games in India, and Rummy Apple is a growing platform that allows players to enjoy exciting rummy games while earning real money. With smooth gameplay, secure transactions, and attractive bonuses, Rummy Apple is a suitable choice for both beginners and experienced rummy players. Download now- https://toprummys.com/rummy-apple/
reply
Rummy Most– Play Online Rummy & Earn Real Money Safely
Online rummy has become one of the most popular skill-based card games in India, and Rummy Most is among the top platforms where players can enjoy rummy games and earn real money. With exciting cash tables, attractive bonuses, and a smooth gaming experience, Rummy Most is a great choice for both beginners and experienced players.
Download now- https://toprummys.com/rummy-most/
reply
Top Rummy's– Discover the Best Rummy Apps to Earn Real Money Online
Online rummy has become one of the most popular skill-based card games in India. Millions of players are now earning real money by playing rummy on trusted mobile apps. If you are looking for a safe and reliable platform to find the best rummy apps, TopRummys is the perfect destination for you.
Visit now- https://toprummys.com
reply
Terra Hill is widely praised on property websites for its rare freehold status, tranquil hillside setting, and modern low-density design in the Pasir Panjang area. The development features around 270 thoughtfully designed residences surrounded by greenery near Kent Ridge Park while remaining just a short walk from Pasir Panjang MRT, providing convenient connectivity to key business hubs and the city centre. With elegant interiors, comprehensive facilities, and proximity to the upcoming Greater Southern Waterfront transformation
reply
The world still seems worth living in, so I'm going to focus a little more on investing and studying.
reply
Expanding your workforce worldwide? Partner with <a href="https://hrbsglobal.com" title="HRBS Global – Employer of Record (EOR) Services" rel="noopener noreferrer">HRBS Global</a> for reliable Employer of Record (EOR) services across borders. We help companies hire, pay, and manage international teams without setting up local entities—ensuring full compliance, seamless onboarding, simplified payroll, and smooth global workforce operations.
reply
The Grand Dunman Showflat offers a stunning introduction to the refined lifestyle that defines Grand Dunman. Property websites frequently highlight its spacious layouts, premium finishes, and elegant interior styling that showcase both comfort and sophistication.
reply
UPPERHOUSE is widely celebrated on property websites for its intimate boutique scale, modern design, and prime location in the Balmoral/Orchard vicinity. Buyers and reviewers alike praise its well-thought-out floorplans, quality finishes, and excellent connectivity to elite schools, shopping, and transport links. With exclusive amenities and a refined residential atmosphere, UPPERHOUSE stands out as a highly desirable choice for sophisticated urban living.
reply
Usually I don't learn article on blogs, but I
wish to say that this write-up very pressured me to check out
and do so! Your writing style has been surprised me. Thank you,
quite great article.
reply
Absolutely loved this article! The way you presented the information made it easy to understand and genuinely enjoyable to read.
reply
I think your blog might be having browser compatibility issues. When I look at your website in Ie, it looks fine but when opening in Internet Explorer, it has some overlapping. I just wanted to give you a quick heads up! Other then that, terrific blog!
reply
Since 2001, We have presented the heritage of our owners but also the way we approach customer service, product handling, and relationships with our customers. Caliber Grocers has grown into a supplier of organic and natural products with distribution centers in the US and Canada. We presently represent over 700 brands across 125 product categories and continue to serve a growing network of consumers and business owners
reply
WHO App is a mobile-first random video chat application that connects users with strangers around the world for live one-on-one video conversations. Distinct from the World Health Organization, WHO App is a social platform designed to facilitate spontaneous connections between individuals seeking casual interactions, flirtation, and friendship.
reply
Similarly, in b9 game apk download unexpected slowdowns may seem like core issues, but careful analysis of performance and system behavior helps identify the true cause and restore smooth gameplay.
reply
Similarly, in<a href="https://b9gameapps.com.pk/">b9 game apk download</a> unexpected slowdowns may seem like core issues, but careful analysis of performance and system behavior helps identify the true cause and restore smooth gameplay.
reply
Man, I feel your pain. Working on deployment pipelines is the same—everyone blames the CI/CD when the code itself is just broken. That line about updates being the cause and solution is so true. Can't wait to hear what the actual bug was!
reply
The Sen is a refined residential development that offers a peaceful and contemporary living experience. With its elegant design, quality finishes, and thoughtfully planned living spaces, it creates a comfortable and stylish lifestyle. The calm surroundings and convenient location make The Sen an excellent choice for modern living and long-term value.
reply
I do agree with all the ideas you have introduced on your post.
They are very convincing and can certainly work. Still, the posts are too brief for novices.
May you please lengthen them a little from next time?
Thank you for the post.
reply
Pinery Residences is a thoughtfully planned residential development that offers a calm and comfortable living environment. With its modern design, quality finishes, and well-designed living spaces, it provides a relaxed and refined lifestyle. Surrounded by greenery and set in a pleasant location, Pinery Residences is an excellent choice for peaceful living and long-term value. <a href="https://www.pineryresidences-official.com.sg/">Pinery Residences</a>
reply
Positive site, where did u come up with the information on this posting?I have read a few of the articles on your website now, and I really like your style. Thanks a million and please keep up the effective work.
reply
<a href="https://emdad031.ir/">امداد خودرو اصفهان</a>
reply
This is an incredibly fascinating and detailed account of a truly peculiar bug! The way you traced the issue through logs, system behavior, and even diving into assembly-level debugging is impressive. It’s amazing how such a seemingly simple problem—like an infinite loop in `ps`—could stem from such a nuanced edge case involving process termination timing. The historical context about QNX and its transition from open-source to corporate ownership adds a layer of depth to the story, highlighting how changes in software ecosystems can impact debugging and development. Your persistence in compiling the old `ps` source code and reproducing the issue is a testament to thorough debugging skills. This kind of deep dive into system-level behavior is both educational and inspiring for anyone working in firmware or low-level software. Great read!
reply
I really love your website.. Pleasant colors & theme.
Did you build this amazing site yourself?
Please reply back as I'm attempting to create my own personal website and would love to learn where you got this from
or what the theme is named. Kudos!
reply
I am a real person, why is every comment here spam? I guess the captcha isn't good enough.
reply
Today, I went to the beach with my kids. I found a sea shell and gave it to my 4 year old daughter and said "You can hear the ocean if you put this to your ear." She put the shell
to her ear and screamed. There was a hermit crab inside and it pinched her
ear. She never wants to go back! LoL I know this is completely off topic but I had to tell someone!
reply
Woah! I'm really digging the template/theme of this website.
It's simple, yet effective. A lot of times it's difficult
to get that "perfect balance" between usability and appearance.
I must say you've done a amazing job with this.
reply
I am really impressed with your writing skills and also with the layout on your blog.
Is this a paid theme or did you modify it yourself?
Anyway keep up the nice quality writing, it is rare to
see a great blog like this one nowadays.
reply
This post is solid, learned a lot from it, thanks for sharing. Really enjoyed this post, you explained the topic clearly and it was easy to follow.
reply
I do not even know how I stopped up right here, however I thought this post
used to be great. I don’t recognise who you’re but certainly you are going to a well-known blogger in case you are not already. Cheers!
reply
Great resource for makers and hobbyists. ImageToSTL.pro is especially helpful when you want to convert a simple logo, shape, or reference image into a printable STL model without opening complex 3D modeling software.
reply
I was suggested this web site by my cousin. I am not sure whether this post is written by him as nobody else know such detailed about my problem. You’re wonderful! Thanks!
reply
Discover everything about the **Teen Patti Game**, including gameplay, rules, card rankings, and winning strategies in one complete guide. Whether you're a beginner or an experienced player, explore helpful resources and updates at <a href="http://rummyteenpattigame.com/" rel="dofollow">Teen Patti Game</a>. Play responsibly and ensure online card games are permitted where you live.
reply